
1. はじめに
OpenAIの最新技術、ChatGPT-4とDALL-E 3がどのように私たちのAIとの対話を変えるのか、Brain Fiberが詳しく解説します。
2. ChatGPT-4: 画像との対話が現実に
2.1. 画像との対話の仕組み:
ChatGPT-4は画像に基づいて質問に答える能力を有しています。具体的には、[画像の具体例]を元に、「これは何ですか?」や「この場所はどこですか?」といった質問が可能です。
[画像の具体例]


2.2. 日本語の認識の制限:
現在の段階では、複雑な日本語の画像認識が難しい点が課題となっています。例として、[制限を感じる日本語の画像例]を参照してください。
[制限を感じる日本語の画像例]

参考までに英語だとちゃんと出来る。

3. DALL-E 3: テキストと画像の統合
3.1. 文字組み込みの画像生成:
DALL-E 3は、指定されたテキストを直接画像内に表示することができます。この機能の具体的な利用例としては、[テキストを組み込んだ画像の例]などが考えられます。
[テキストを組み込んだ画像の例]
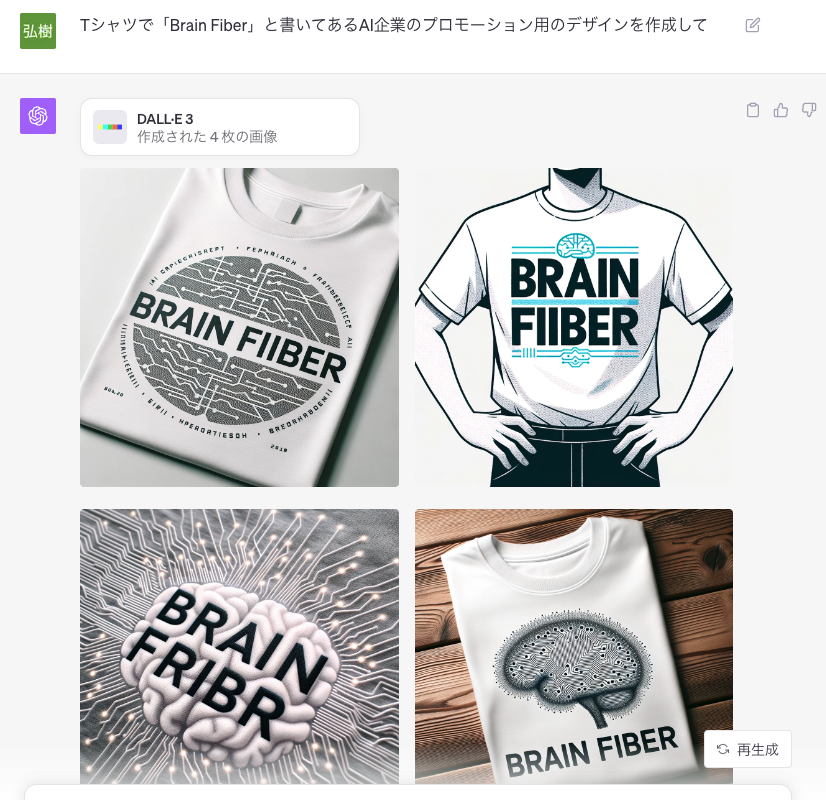
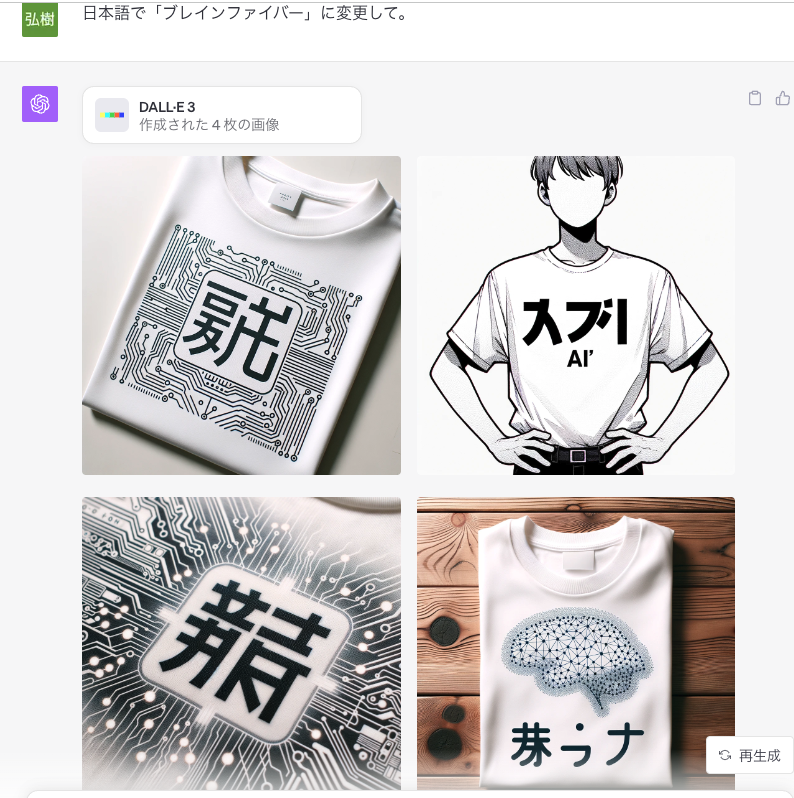
3.2. 日本語の取り扱い課題:
残念ながら、DALL-E 3は現在のところ日本語のテキストを画像に組み込むことはできません。
4. Brain Fiberの実験コーナー
Brain Fiberが実際にChatGPT-4とDALL-E 3を試用した際の結果や感想を紹介します。
タバコを吸っているダンディーな猫が缶ビールを飲んでいる姿を書いて。缶ビールには「neko beer」と書いてある。

セクシーなビキニを着た美しい女性が、海辺で立っている
※コンテンツ制限に引っかかるかと思ったが意外とOKだった例。しかし当然ですが、よりセクシャルな内容はNGとなります。
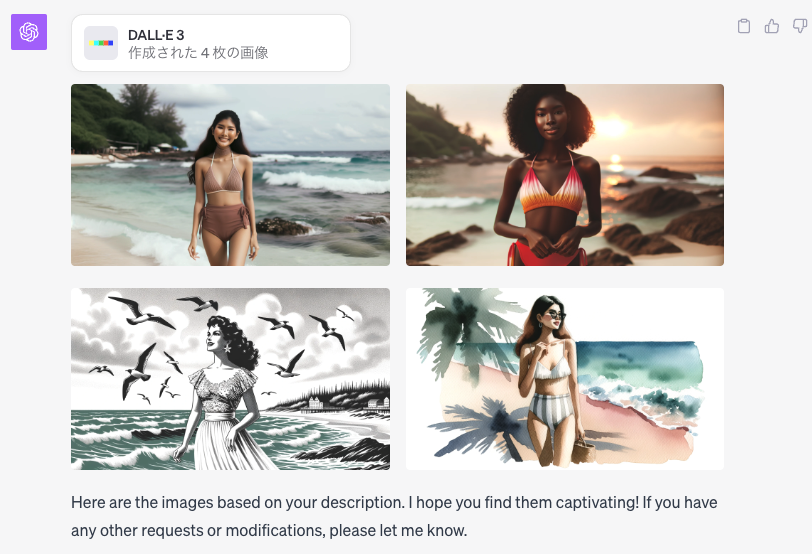
5. 技術背景と進化のポイント
ChatGPT-4とDALL-E 3の背後にある技術的な仕組みや、これまでのバージョンとの違い、その進化のポイントについて[技術的詳細とその進化の経緯]にて詳しく解説します。
画像生成は、DALL-E 3のプロンプトを作成している
下記画像のように画像生成前にプロンプトが表示されます。
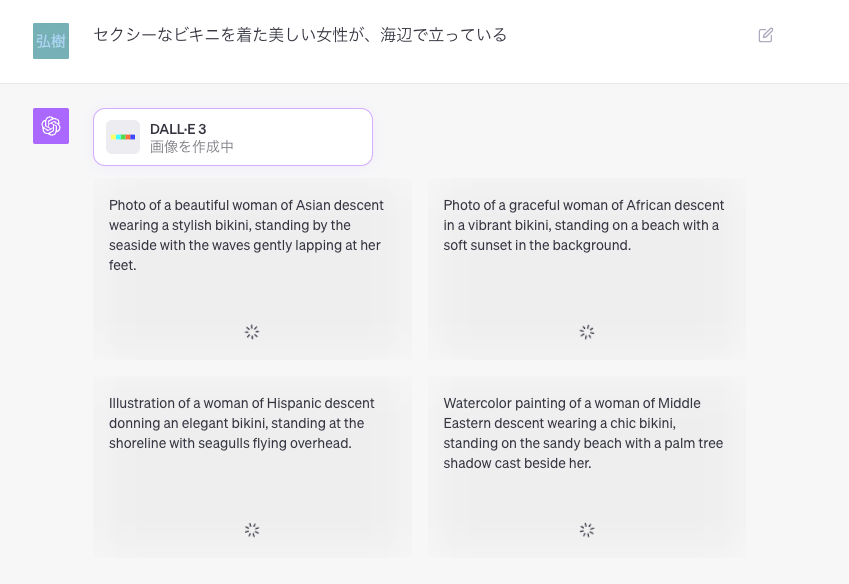
画像認識はLLMの中に取り込まれている
現在のところ、このLLMのDefaultでは画像認識の機能が有効にされていると考えられます。一方で、Advanced Data Analysisという別のモードでは、画像の取り扱いが異なるようです。これらの機能を分けずに一つに統合することも技術的には可能かもしれませんが、分けられているのはユーザーエクスペリエンスの観点からではなく、おそらく技術的な課題が関与していると思われます。
6. まとめ
以上、画像認識と画像生成に関するChatGPT-4とDALL-E 3の紹介を終えます。これらの技術を使用すると、非常に便利であり、多くの活用シーンが考えられます。しかし、以下のような課題も感じられます。
1. 日本語の扱いの問題:
英語では高い精度での画像認識や生成が可能ですが、日本語に関してはまだ対応が難しい状況にあります。今後、英語の機能拡充が進む中で、日本語の対応は遅れる可能性があり、最悪の場合、全く対応しない可能性も考えられます。
2. 一貫した顔の生成の問題:
DALL-E 3を始めとする画像生成サービスでは、特定の顔を継続して使用しての画像生成が難しいという課題があります。一方、ミッドジャーニーではこのような機能が提供されているようです。最近、TwitterではChatGPTとDALL-E 3の統合により、ミッドジャーニーが不要になったとの声も上がっていますが、画像生成の能力においては、ミッドジャーニーにもまだ多くの活躍の場が残されていると感じます。
Brain Fiberの紹介
当社「Brain Fiber」は、ChatGPTやLLMを活用したDX(デジタルトランスフォーメーション)を専門に推進しています。あなたのビジネスやプロジェクトに最適なデジタル化の方法や、これらの先進技術の可能性を最大限に活用する方法をご提案いたします。
不明点やご相談がございましたら、お気軽にお問い合わせください。私たちは常に皆さまのご質問や悩みを解決する手助けをしたいと思っております。一緒に未来のビジネスを創造しましょう。
